Tasty Bytes - Introduzione a Snowpark per la data science
Panoramica
In questo quickstart Introduzione a Snowpark per la data science, aiuterai l’azienda di food truck fittizia Tasty Bytes ad aumentare le vendite addestrando un modello per fornire consigli sulle posizioni ai conducenti dei food truck. Utilizzerai Snowpark per Python per preparare i dati, addestrare un modello e distribuirlo. Una volta distribuito, creerai un prototipo di applicazione utilizzando Streamlit per dimostrare come i conducenti dei food truck potrebbero usare questo modello per trovare la posizione migliore in cui parcheggiare per il prossimo turno.
Che cos’è Snowpark?
Snowpark consente agli sviluppatori di eseguire query e creare applicazioni basate sui dati in Python, Java e Scala tramite API e costrutti di programmazione in stile DataFrame che vengono eseguiti sul motore elastico di Snowflake. Scopri di più su Snowpark.
Che cos’è Streamlit?
Streamlit (acquisito da Snowflake a marzo 2022) è una libreria Python che consente di creare e condividere facilmente app web personalizzate. Scopri di più su Streamlit.
Cosa imparerai
- Come accedere a dati di terze parti dal Marketplace Snowflake
- Come esplorare i dati ed eseguire il feature engineering con le Snowpark DataFrame API
- Come addestrare un modello in Snowflake con una stored procedure
- Come distribuire un modello in Snowflake sotto forma di User Defined Function per l’inferenza del modello
- Come creare un’app Streamlit per interagire con il modello
Prerequisiti
- Git installato
- Anaconda installato
- Account Snowflake con i pacchetti Anaconda abilitati da ORGADMIN. Se non hai un account Snowflake, puoi registrarti per una prova gratuita.
- Un login per l’account Snowflake con il ruolo ACCOUNTADMIN. In caso contrario, dovrai registrarti per una prova gratuita oppure utilizzare un ruolo diverso con la capacità di creare database, schemi, tabelle, stage, User Defined Function e stored procedure.
Cosa realizzerai
-
Una previsione delle vendite per posizione
-
Un’applicazione Streamlit per trovare le posizioni con le migliori previsioni di vendita
Configurare i dati in Snowflake
Panoramica
Utilizzerai Snowsight, l’interfaccia web di Snowflake, per:
- Accedere ai dati sulle posizioni di SafeGraph dal Marketplace Snowflake
- Creare oggetti Snowflake (warehouse, database, schema)
- Caricare dati sulle vendite per turno da S3
- Fare il join delle vendite per turno con i dati sulle posizioni di SafeGraph
Tasty Bytes gestisce food truck in molte città di tutto il mondo e ogni food truck può scegliere due posizioni di vendita al giorno. Le posizioni corrispondono a punti di interesse di SafeGraph. Il tuo scopo è fare il join di latitudine e longitudine nei dati SafeGraph ottenuti dal Marketplace ai tuoi dati sulle vendite per turno per utilizzarli come feature nell’addestramento dei modelli.
Passaggio 1 - Acquisire i dati sui punti di interesse di SafeGraph dal Marketplace Snowflake
-
Accedi al tuo account Snowflake.
-
Segui i passaggi e il video qui di seguito per accedere al prodotto SafeGraph nel Marketplace dal tuo account Snowflake.
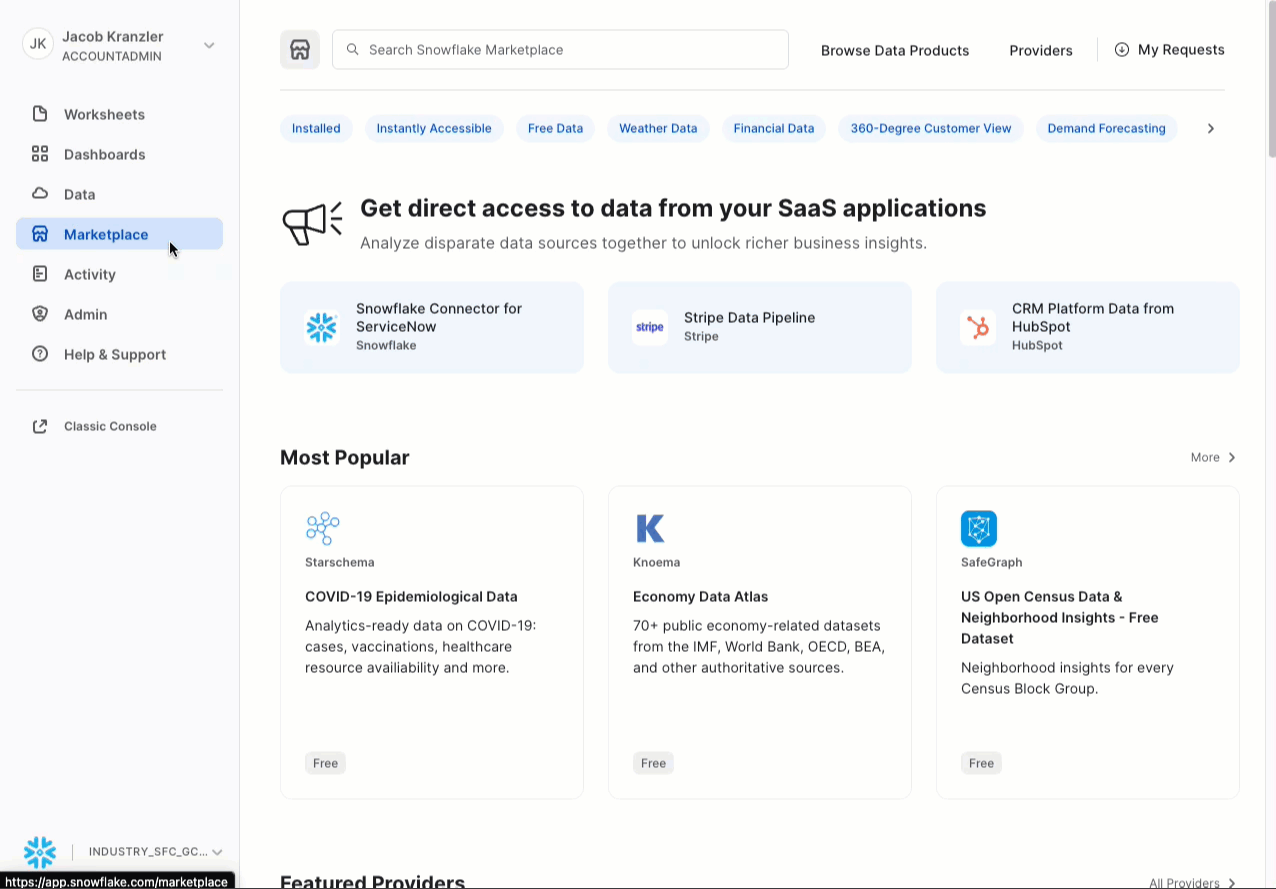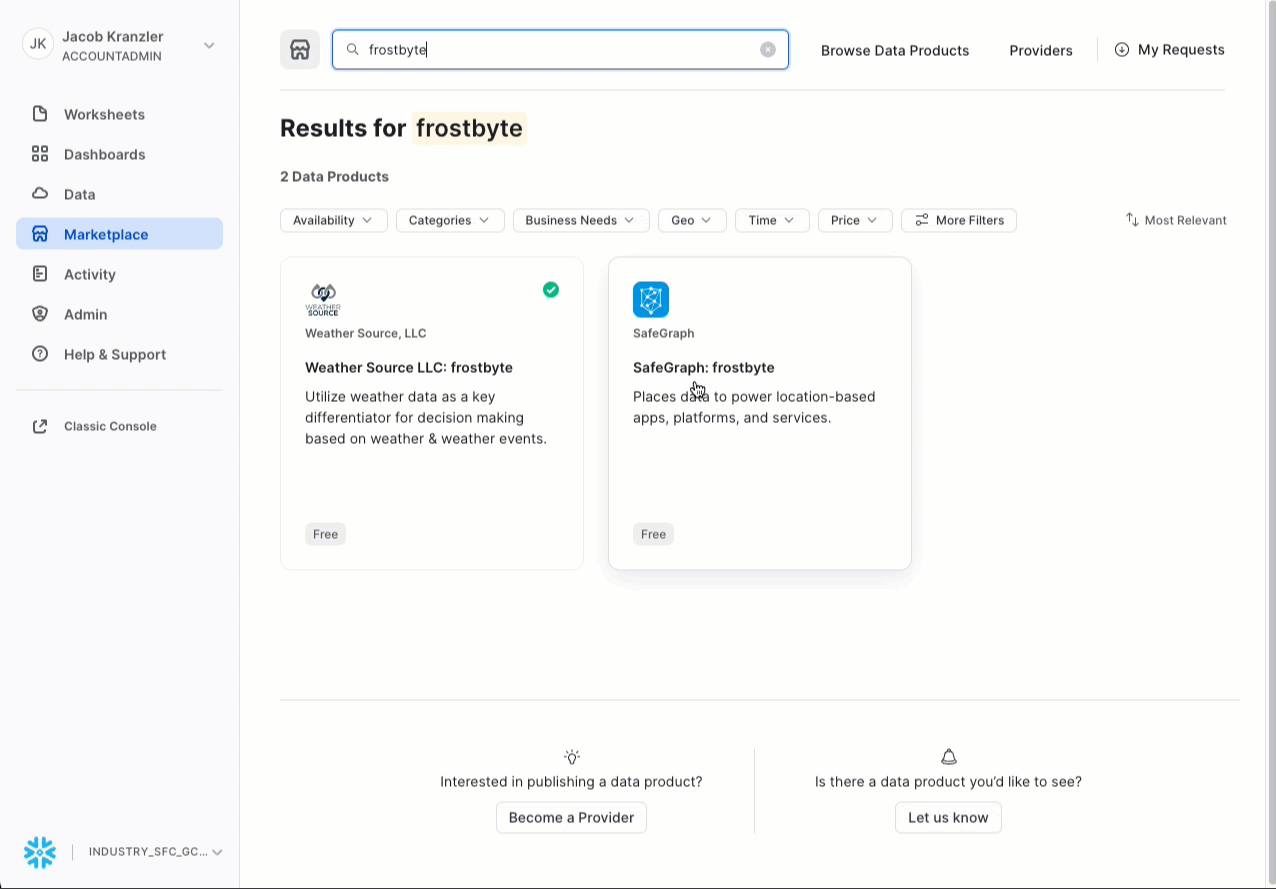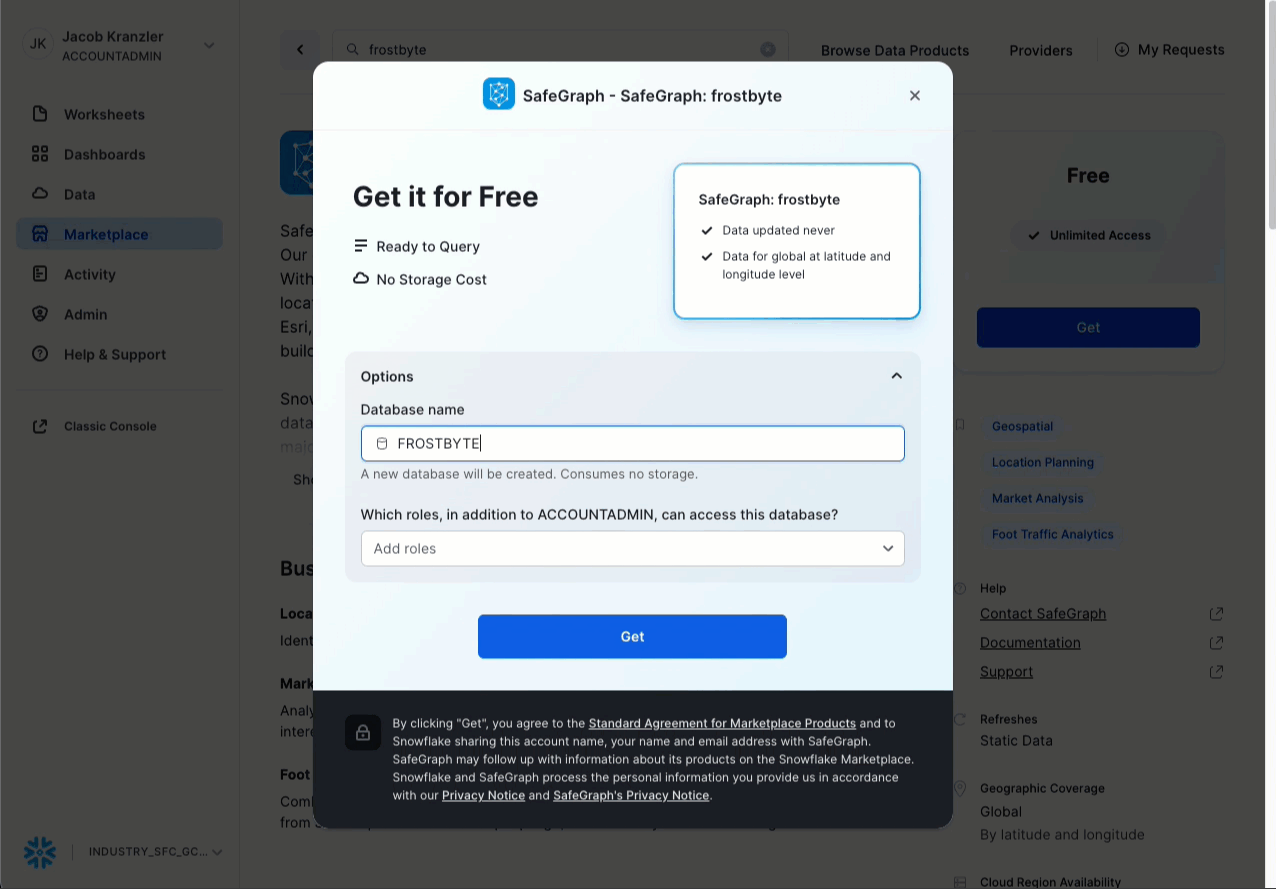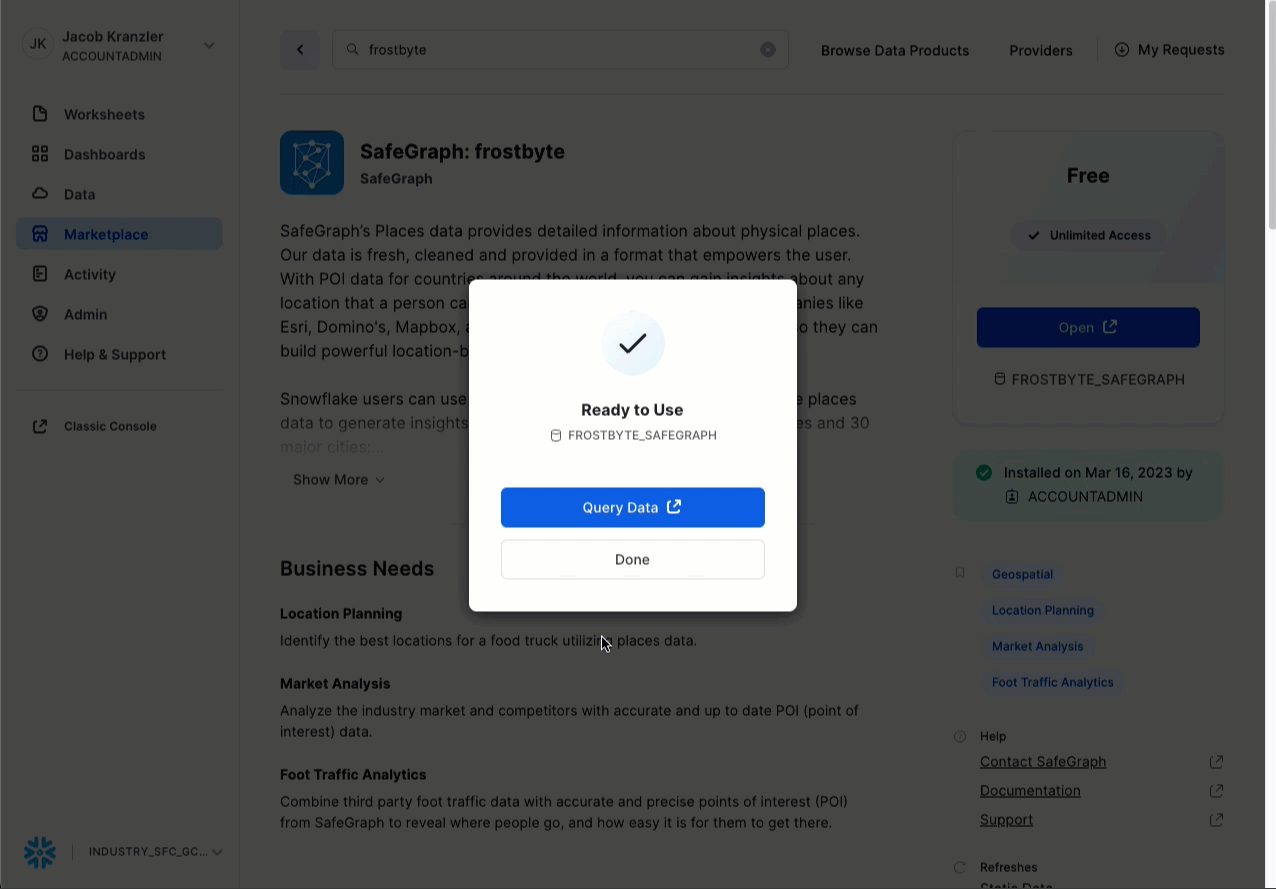
- Fai clic su -> Icona Home
- Fai clic su -> Marketplace
- Cerca -> frostbyte
- Fai clic su -> SafeGraph: frostbyte
- Fai clic su -> Get
- Rinomina il database -> FROSTBYTE_SAFEGRAPH (tutte maiuscole)
- Consenti l’accesso ad altri ruoli -> PUBLIC
aside positive SafeGraph è un’azienda globale di dati geospaziali che offre dati su qualsiasi località nel mondo. Clienti come Esri, Tripadvisor, Mapbox e Sysco utilizzano i dati di SafeGraph per comprendere meglio i propri clienti, creare nuovi prodotti e prendere decisioni migliori per il proprio business.
Passaggio 2 - Creare oggetti, caricare i dati e unire i dati
- Vai a Worksheets, fai clic su “+” nell’angolo superiore destro per creare un nuovo foglio di lavoro e scegli “SQL Worksheet”.
- Incolla ed esegui questo codice SQL nel foglio di lavoro per creare oggetti Snowflake (warehouse, database, schema), caricare i dati delle vendite per turno da S3 e unire i dati delle vendite per turno con i dati sulle posizioni di SafeGraph.
USE ROLE accountadmin; -- create a development database for data science work CREATE OR REPLACE DATABASE frostbyte_tasty_bytes_dev; -- create raw, harmonized, and analytics schemas -- raw zone for data ingestion C REATE OR REPLACE SCHEMA frostbyte_tasty_bytes_dev.raw; -- harmonized zone for data processing CREATE OR REPLACE SCHEMA frostbyte_tasty_bytes_dev.harmonized; -- analytics zone for development CREATE OR REPLACE SCHEMA frostbyte_tasty_bytes_dev.analytics; -- create csv file format CREATE OR REPLACE FILE FORMAT frostbyte_tasty_bytes_dev.raw.csv_ff type = 'csv'; -- create an external stage pointing to S3 CREATE OR REPLACE STAGE frostbyte_tasty_bytes_dev.raw.s3load COMMENT = 'Quickstarts S3 Stage Connection' url = 's3://sfquickstarts/frostbyte_tastybytes/' file_format = frostbyte_tasty_bytes_dev.raw.csv_ff; -- define shift sales table CREATE OR REPLACE TABLE frostbyte_tasty_bytes_dev.raw.shift_sales( location_id NUMBER(19,0), city VARCHAR(16777216), date DATE, shift_sales FLOAT, shift VARCHAR(2), month NUMBER(2,0), day_of_week NUMBER(2,0), city_population NUMBER(38,0) ); -- create and use a compute warehouse CREATE OR REPLACE WAREHOUSE tasty_dsci_wh AUTO_SUSPEND = 60; USE WAREHOUSE tasty_dsci_wh; -- ingest from S3 into the shift sales table COPY INTO frostbyte_tasty_bytes_dev.raw.shift_sales FROM @frostbyte_tasty_bytes_dev.raw.s3load/analytics/shift_sales/; -- join in SafeGraph data CREATE OR REPLACE TABLE frostbyte_tasty_bytes_dev.harmonized.shift_sales AS SELECT a.location_id, a.city, a.date, a.shift_sales, a.shift, a.month, a.day_of_week, a.city_population, b.latitude, b.longitude FROM frostbyte_tasty_bytes_dev.raw.shift_sales a JOIN frostbyte_safegraph.public.frostbyte_tb_safegraph_s b ON a.location_id = b.location_id; -- promote the harmonized table to the analytics layer for data science development CREATE OR REPLACE VIEW frostbyte_tasty_bytes_dev.analytics.shift_sales_v AS SELECT * FROM frostbyte_tasty_bytes_dev.harmonized.shift_sales; -- view shift sales data SELECT * FROM frostbyte_tasty_bytes_dev.analytics.shift_sales_v;
Data Science con Snowpark
Panoramica
Tasty Bytes intende ottenere una crescita annuale delle vendite del 25% per cinque anni. Per supportare questo obiettivo e massimizzare i ricavi giornalieri in tutta la flotta di food truck, il team di data science deve creare un modello ML per dirigere i food truck verso le posizioni in cui si prevedono le vendite più elevate per un dato turno.
- Il notebook tasty_bytes_snowpark_101.ipynb contiene alcune feature e funzioni fondamentali di un flusso di lavoro di data science di base utilizzando Snowpark per Python.
- Svolgerai i seguenti passaggi nel ruolo di un data scientist di Tasty Bytes incaricato di creare e distribuire un modello su Snowflake per consigliare le posizioni migliori in cui parcheggiare i furgoni.
- Principi di base di Snowpark
- Connessione a Snowflake
- Esplorazione dell’API e dei DataFrame
- Esplorazione dei dati e feature engineering
- Funzioni di aggregazione
- Imputazione, codifica e suddivisione tra addestramento e test
- Addestramento e distribuzione di modelli
- Addestramento in una stored procedure
- Scalabilità elastica
- Distribuzione di una User Defined Function per l’inferenza del modello
- Principi di base di Snowpark
Passaggio 1 - Clonare il repository GitHub
Clona il repository GitHub. Questo repository contiene tutto il codice che ti servirà per completare questo quickstart.
$ git clone https://github.com/Snowflake-Labs/sfguide-tasty-bytes-snowpark-101-for-data-science.git
Passaggio 2 - Aggiornare il file di autorizzazione
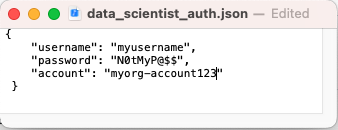
- Aggiorna il file data_scientist_auth.json con le credenziali del tuo account Snowflake. Il notebook Python utilizzerà questo file per accedere alle tue credenziali e connettersi a Snowflake.
aside positive
Per il parametroaccount, usa il tuo ID account. Nota che l’ID account non include il suffisso snowflakecomputing.com.
Passaggio 3 - Creare l’ambiente Python
aside positive Queste istruzioni utilizzano Anaconda per creare l’ambiente Python. Tuttavia, puoi usare qualsiasi altro ambiente Python con Python 3.8, ad esempio virtualenv.
aside negative Apple M1: l’esecuzione di Snowpark Python sui chip Apple M1 presenta un problema noto, dovuto alla gestione della memoria in pyOpenSSL. Per risolvere questo problema, consulta la documentazione di Snowpark.
Dal Terminale, esegui i seguenti comandi per creare l’ambiente Python e lanciare il notebook Jupyter:
i. Crea un ambiente Python 3.8 chiamato “py38_env_tb1” (tb1 = Tasty Bytes 1) utilizzando pacchetti (e versioni) provenienti dal canale Snowflake Anaconda
conda create --name py38_env_tb1 --override-channels -c https://repo.anaconda.com/pkgs/snowflake python=3.8
ii. Attiva l’ambiente py38_env_tb1
conda activate py38_env_tb1
iii. Installa il pacchetto Snowpark Python e i pacchetti che verranno utilizzati nelle funzioni distribuite su Snowflake dal canale Snowflake Anaconda
conda install -c https://repo.anaconda.com/pkgs/snowflake snowflake-snowpark-python numpy pandas scikit-learn joblib cachetools
v. Installa i pacchetti che verranno utilizzati solo nell’ambiente Python (ossia interfaccia utente, visualizzazione…)
pip install streamlit matplotlib plotly notebook
vi. Vai al repository GitHub clonato ed esegui il notebook Jupyter
jupyter notebook
Passaggio 4 - Eseguire il notebook Jupyter
- Apri ed esegui le celle di tasty_bytes_snowpark_101.ipynb nel notebook Jupyter.
Risoluzione dei problemi
-
Problemi legati a PyArrow: disinstalla
pyarrowprima di installare Snowpark. -
Build alternativa dell’ambiente Python dal file environment.yml:
i. Nel Terminale, vai al repository GitHub clonato e crea l’ambiente
conda env create -f environment.ymlii . Attiva l’ambiente
conda activate py38_env_tb1iii. Esegui il notebook Jupyter
jupyter notebook
Prototipo di applicazione con Streamlit
Panoramica
Ora che hai distribuito un modello che prevede le vendite di ogni posizione per il prossimo turno, devi trovare un modo per consentire ai conducenti dei food truck di utilizzare queste previsioni per scegliere le posizioni migliori dove parcheggiare. Devi creare un prototipo di applicazione per mostrare al team di progettazione come un conducente potrebbe interagire con il modello di previsione delle vendite per turno. L’applicazione consentirà a un utente di scegliere una città e un turno (mattina o pomeriggio) e mostrerà le vendite previste per ogni posizione su una mappa.
Passaggio 1 - Verificare i prerequisiti
- L’app Streamlit utilizza l’ambiente Python, il file di autenticazione e la User Defined Function del passaggio 3. Verifica i seguenti requisiti:
- L’ambiente Python 3.8 py38_env_tb1 è stato creato.
- Il file data_scientist_auth.json è stato compilato.
- Il notebook tasty_bytes_snowpark_101.ipynb è stato eseguito.
Passaggio 2 - Facoltativo: rivedere il codice
- Apri streamlit_app.py
- Identifica il punto in cui si verifica la connessione a Snowflake.
- Identifica il punto in cui viene richiamata la User Defined Function di inferenza del modello per fornire previsioni immediate sulle vendite per turno.
Passaggio 3 - Eseguire l’app
- Nel Terminale, vai al repository GitHub clonato e attiva l’ambiente Python py38_env_tb1
conda activate py38_env_tb1
- Avvia l’applicazione
streamlit run streamlit_app.py
- Utilizza il menu a discesa per selezionare una città e visualizzare i consigli aggiornati.
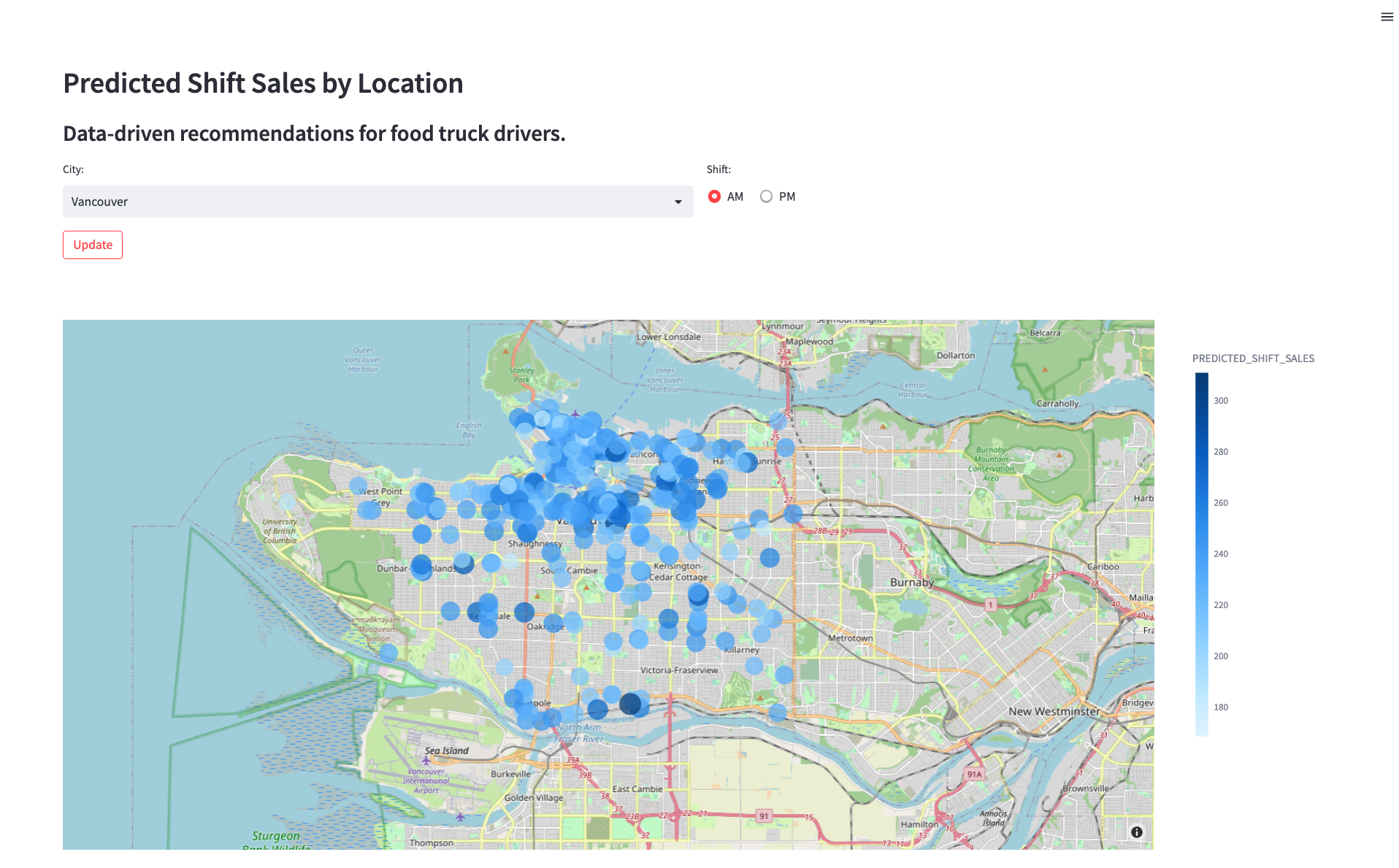
Pulizia
Panoramica degli oggetti creati in questo quickstart
Snowflake:
- Warehouse: tasty_dsci_wh
- Database: frostbyte_tasty_bytes_dev
- Schema: dati grezzi
- Tabella: frostbyte_tasty_bytes_dev.raw.shift_sales
- Stage: frostbyte_tasty_bytes_dev.raw.s3load
- Formato file: frostbyte_tasty_bytes_dev.raw.csv_ff
- Schema: armonizzato
- Tabella: frostbyte_tasty_bytes_dev.harmonized.shift_sales
- Schema: analitico
- Tabelle:
- frostbyte_tasty_bytes_dev.analytics.shift_sales_train
- frostbyte_tasty_bytes_dev.analytics.shift_sales_test
- Vista: frostbyte_tasty_bytes_dev.analytics.shift_sales_v
- Stage: frostbyte_tasty_bytes_dev.analytics.model_stage
- Procedura: sproc_train_linreg
- Funzione: udf_linreg_predict_location_sales
- Database condiviso: frostbyte_safegraph
- Tabella: frostbyte_safegraph.public.frostbyte_tb_safegraph_s
Anaconda: - Ambiente Python py38_env_tb1
GitHub: - Repository clonato: sfguide-tasty-bytes-snowpark-101-for-data-science
Passaggio 1 - Rimuovere gli oggetti Snowflake
- Vai a Worksheets, fai clic su “+” nell’angolo superiore destro per creare un nuovo foglio di lavoro e scegli “SQL Worksheet”.
- Incolla ed esegui il seguente codice SQL nel foglio di lavoro per fare il drop degli oggetti Snowflake creati in questo quickstart.
USE ROLE accountadmin; DROP PROCEDURE IF EXISTS frostbyte_tasty_bytes.analytics.sproc_train_linreg(varchar, array, varchar, varchar); DROP FUNCTION IF EXISTS frostbyte_tasty_bytes.analytics.udf_linreg_predict_location_sales(float, float, float, float, float, float, float, float); DROP DATABASE IF EXISTS frostbyte_tasty_bytes_dev; DROP DATABASE IF EXISTS frostbyte_safegraph; DROP WAREHOUSE IF EXISTS tasty_dsci_wh;
Passaggio 2 - Rimuovere l’ambiente Python
- Nel Terminale, esegui:
conda remove --name py38_env_tb1 --all
Passaggio 3 - Rimuovere il repository GitHub clonato
- Nel Terminale, dalla directory in cui è stato clonato il repository GitHub, esegui:
rm -rf sfguide-tasty-bytes-snowpark-101-for-data-science
Conclusione e fasi successive
Conclusione
Ecco fatto! Hai completato il quickstart Tasty Bytes - Introduzione a Snowpark per la data science.
In questo quickstart hai:
- Acquisito dati SafeGraph sui punti di interesse dal Marketplace Snowflake
- Esplorato i dati ed eseguito il feature engineering con Snowpark
- Addestrato un modello in Snowflake con una stored procedure
- Distribuito un modello sotto forma di User Defined Function
- Creato un’applicazione Streamlit per fornire previsioni immediate sulle vendite per turno in base alla posizione
Fasi successive
Per continuare il tuo percorso nel Data Cloud Snowflake, visita il link qui sotto per vedere gli altri quickstart Powered by Tasty Bytes disponibili.
This content is provided as is, and is not maintained on an ongoing basis. It may be out of date with current Snowflake instances