Tasty Bytes – Snowpark 101 pour la Data Science
Présentation
Dans ce guide Quickstart Snowpark 101 pour la Data Science, vous allez aider l’entreprise fictive de food trucks Tasty Bytes à accroître ses ventes en entraînant un modèle destiné à fournir des recommandations d’emplacements aux chauffeurs des camionnettes. Vous allez utiliser Snowpark for Python pour préparer les données, mais aussi pour entraîner et déployer un modèle. Une fois celui-ci déployé, vous créerez un prototype d’application à l’aide de Streamlit afin de montrer comment les chauffeurs des camionnettes pourraient utiliser le modèle pour trouver le meilleur emplacement de stationnement à chaque fois.
Qu’est-ce que Snowpark ?
Snowpark permet aux développeurs d’interroger et de créer des applications de données en Python, Java et Scala via des API et des constructions de programmation de type DataFrame qui s’exécutent sur le moteur élastique de Snowflake. Pour en savoir plus sur Snowpark, cliquez ici.
Qu’est-ce que Streamlit ?
Streamlit (dont Snowflake a fait l’acquisition en mars 2022) est une bibliothèque Python qui permet de créer et de partager facilement des applications Web personnalisées. Pour en savoir plus sur Streamlit, cliquez ici.
Vous allez apprendre :
- Comment accéder à des données tierces dans la Data Marketplace Snowflake
- Comment explorer des données et exécuter le feature engineering avec les API DataFrame Snowpark
- Comment entraîner un modèle dans Snowflake à l’aide d’une procédure stockée
- Comment déployer un modèle dans Snowflake vers une fonction définie par l’utilisateur pour l’inférence du modèle
- Comment créer une application Streamlit pour interagir avec le modèle
Conditions préalables
- Git doit être installé.
- Anaconda doit être installé.
- Vous devez posséder un compte Snowflake comprenant des packages Anaconda activés par ORGADMIN. Si vous n’avez pas de compte Snowflake, vous pouvez créer un compte d’essai gratuit.
- Vous devez vous connecter à un compte Snowflake avec le rôle ACCOUNTADMIN. Sinon, vous devez créer un compte d’essai gratuit ou utiliser un autre rôle capable de créer une base de données, un schéma, des tables, des zones de préparation, des fonctions définies par l’utilisateur et des procédures stockées.
Vous allez créer :
-
Des prévisions de ventes par emplacement
-
Une application Streamlit pour trouver les meilleurs emplacements selon les prévisions de ventes
Configuration des données dans Snowflake
Présentation
Vous allez utiliser Snowsight, l’interface Web de Snowflake, pour :
- Accéder aux données de localisation de SafeGraph à partir de la Marketplace Snowflake
- Créer des objets Snowflake (entrepôt, base de données, schéma)
- Intégrer des données de ventes par équipe à partir de S3
- Associer les données de ventes par équipe aux données de localisation de SafeGraph
Tasty Bytes exploite des food trucks dans des villes du monde entier, chaque camionnette ayant la possibilité de choisir deux emplacements différents chaque jour. Les emplacements sont associés aux points d’intérêt de SafeGraph. Vous souhaitez associer à vos données de ventes par équipe la latitude et la longitude des données SafeGraph de la Marketplace afin de les utiliser en tant que fonctionnalités dans l’entraînement du modèle.
Étape 1 – Acquérir des données de points d’intérêt SafeGraph à partir de la Marketplace Snowflake
-
Connectez-vous à votre compte Snowflake.
-
Suivez les étapes et la vidéo ci-dessous pour accéder à l’annonce de SafeGraph sur la Marketplace dans votre compte Snowflake.
- Cliquez sur -> l’icône Home (Accueil).
- Cliquez sur -> Marketplace.
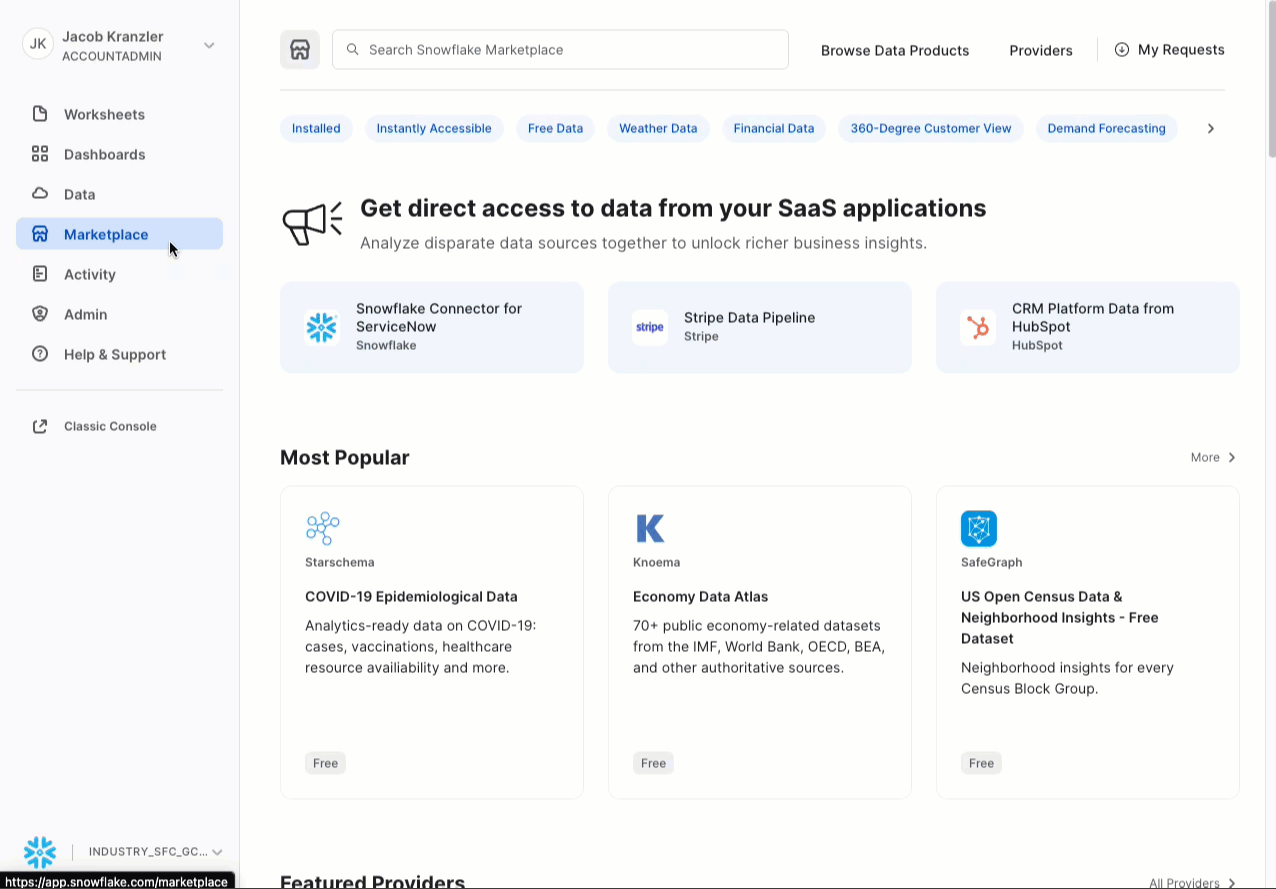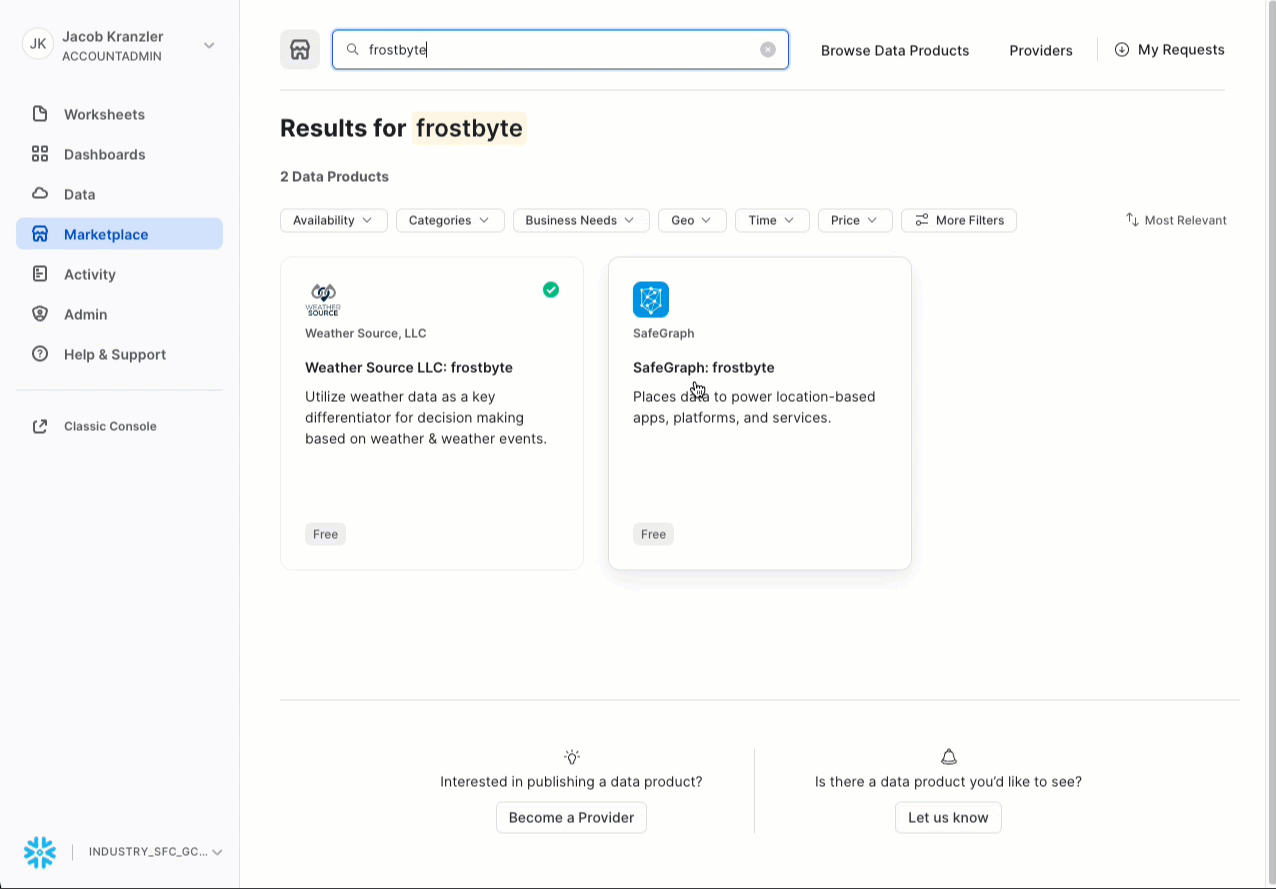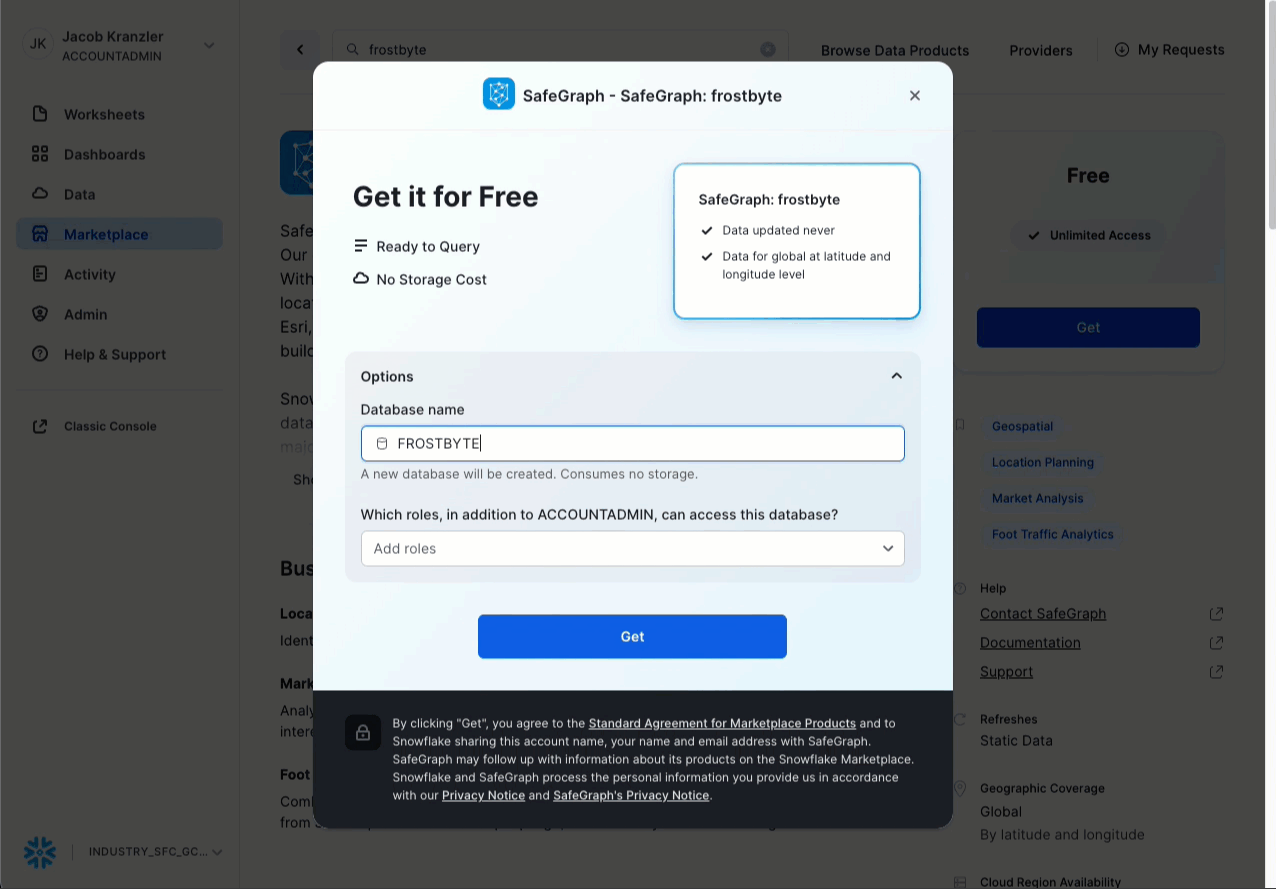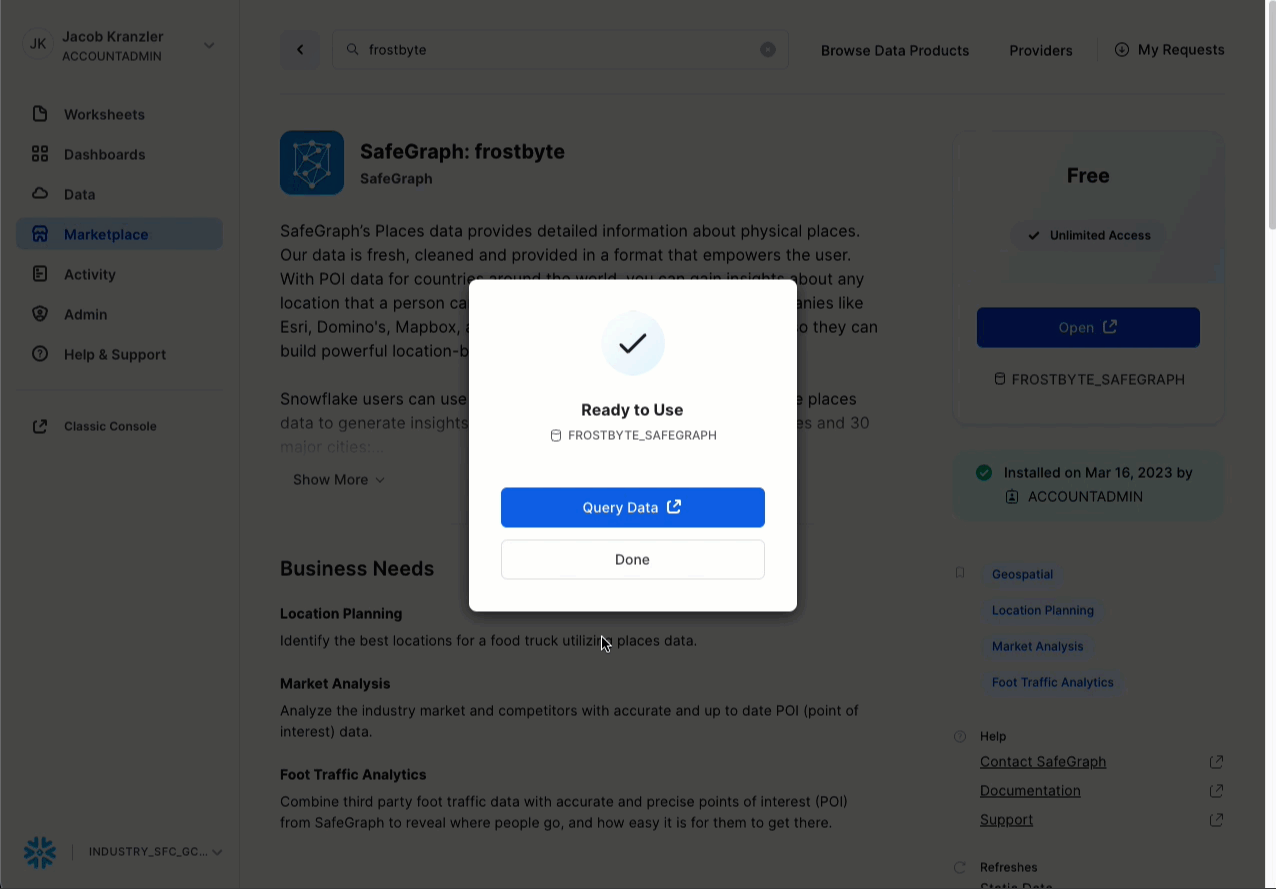
- Recherchez -> frostbyte.
- Cliquez sur -> SafeGraph: frostbyte.
- Cliquez sur -> Get (Obtenir).
- Renommez la base de données -> FROSTBYTE_SAFEGRAPH (en lettres majuscules).
- Attribuez des rôles supplémentaires > PUBLIC.
aside positive SafeGraph est une entreprise mondiale de données géospatiales qui offre des données sur n’importe quel endroit dans le monde. Des entreprises comme Esri, Tripadvisor, Mapbox et Sysco utilisent les données de SafeGraph pour mieux comprendre leurs clients, créer de nouveaux produits et prendre des décisions plus avisées concernant leur activité.
Étape 2 – Créer des objets, charger des données et associer des données
- Accédez aux feuilles de calcul, cliquez sur « + » dans le coin supérieur droit pour créer une nouvelle feuille de calcul, puis choisissez « SQL Worksheet » (Feuille de calcul SQL).
- Collez et exécutez l’instruction SQL suivante dans la feuille de calcul pour créer des objets Snowflake (entrepôt, base de données, schéma), intégrer les données de ventes par équipe à partir de S3 et associer les données de ventes par équipe aux données de localisation de SafeGraph.
USE ROLE accountadmin; -- create a development database for data science work CREATE OR REPLACE DATABASE frostbyte_tasty_bytes_dev; -- create raw, harmonized, and analytics schemas -- raw zone for data ingestion CREATE OR REPLACE SCHEMA frostbyte_tasty_bytes_dev.raw; -- harmonized zone for data processing CREATE OR REPLACE SCHEMA frostbyte_tasty_bytes_dev.harmonized; -- analytics zone for development CREATE OR REPLACE SCHEMA frostbyte_tasty_bytes_dev.analytics; -- create csv file format CREATE OR REPLACE FILE FORMAT frostbyte_tasty_bytes_dev.raw.csv_ff type = 'csv'; -- create an external stage pointing to S3 CREATE OR REPLACE STAGE frostbyte_tasty_bytes_dev.raw.s3load COMMENT = 'Quickstarts S3 Stage Connection' url = 's3://sfquickstarts/frostbyte_tastybytes/' file_format = frostbyte_tasty_bytes_dev.raw.csv_ff; -- define shift sales table CREATE OR REPLACE TABLE frostbyte_tasty_bytes_dev.raw.shift_sales( location_id NUMBER(19,0), city VARCHAR(16777216), date DATE, shift_sales FLOAT, shift VARCHAR(2), month NUMBER(2,0), day_of_week NUMBER(2,0), city_population NUMBER(38,0) ); -- create and use a compute warehouse CREATE OR REPLACE WAREHOUSE tasty_dsci_wh AUTO_SUSPEND = 60; USE WAREHOUSE tasty_dsci_wh; -- ingest from S3 into the shift sales table COPY INTO frostbyte_tasty_bytes_dev.raw.shift_sales FROM @frostbyte_tasty_bytes_dev.raw.s3load/analytics/shift_sales/; -- join in SafeGraph data CREATE OR REPLACE TABLE frostbyte_tasty_bytes_dev.harmonized.shift_sales AS SELECT a.location_id, a.city, a.date, a.shift_sales, a.shift, a.month, a.day_of_week, a.city_population, b.latitude, b.longitude FROM frostbyte_tasty_bytes_dev.raw.shift_sales a JOIN frostbyte_safegraph.public.frostbyte_tb_safegraph_s b ON a.location_id = b.location_id; -- promote the harmonized table to the analytics layer for data science development CREATE OR REPLACE VIEW frostbyte_tasty_bytes_dev.analytics.shift_sales_v AS SELECT * FROM frostbyte_tasty_bytes_dev.harmonized.shift_sales; -- view shift sales data SELECT * FROM frostbyte_tasty_bytes_dev.analytics.shift_sales_v;
Data Science avec Snowpark
Présentation
Tasty Bytes vise une croissance des ventes de 25 % par an sur cinq ans. Pour atteindre cet objectif et optimiser les revenus quotidiens de la flotte de camionnettes, l’équipe data science doit concevoir un modèle de ML pour orienter les camionnettes vers les emplacements où les ventes devraient être les plus élevées sur une période de travail donnée.
- Le notebook tasty_bytes_snowpark_101.ipynb traite des fonctionnalités/fonctions fondamentales d’un workflow de data science de base utilisant Snowpark for Python.
- Suivez les étapes suivantes en tant que data scientist de Tasty Bytes à qui il a été demandé de créer et de déployer un modèle sur Snowflake afin de recommander les meilleurs emplacements de stationnement pour les food trucks.
- Éléments de base Snowpark
- Se connecter à Snowflake
- Explorer l’API et les DataFrames
- Exploration de données et feature engineering
- Fonctions d’agrégation
- Imputation, codage et décomposition des données à des fins d’entraînement/de test
- Entraînement et déploiement du modèle
- Entraînement dans une procédure stockée
- Évolutivité élastique
- Déploiement d’une fonction définie par l’utilisateur pour l’inférence de modèle
- Éléments de base Snowpark
Étape 1 – Cloner le référentiel GitHub
Clonez le référentiel GitHub. Le référentiel contient tout le code dont vous aurez besoin pour terminer ce guide Quickstart.
$ git clone https://github.com/Snowflake-Labs/sfguide-tasty-bytes-snowpark-101-for-data-science.git
Étape 2 – Mettre à jour le fichier d’autorisation
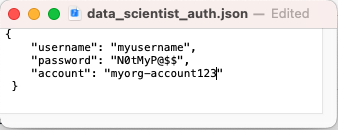
- Mettez à jour le fichier data_scientist_auth.json avec vos identifiants de compte Snowflake. Le notebook Python utilisera ce fichier pour accéder à vos identifiants et se connecter à Snowflake.
aside positive
Pour le paramètreaccount(Compte), utilisez votre identificateur de compte. Notez que l’identificateur de compte ne comprend pas le suffixe snowflakecomputing.com.
Étape 3 – Créer l’environnement Python
aside positive Les instructions suivantes utilisent Anaconda pour créer l’environnement Python. Vous pouvez utiliser un autre environnement Python avec Python 3.8, par exemple, virtualenv.
aside negative Apple M1 : il existe un problème connu d’exécution de Snowpark Python sur les puces Apple M1 en raison de la gestion de la mémoire dans pyOpenSSL. Reportez-vous à la documentation Snowpark correspondante pour résoudre ce problème.
Sur le terminal, procédez comme suit pour créer l’environnement Python et lancer le notebook Jupyter :
i. Créez un environnement Python 3.8 appelé « py38_env_tb1 » (tb1 = Tasty Bytes 1) à l’aide de packages (et versions) du canal Anaconda Snowflake.
conda create --name py38_env_tb1 --override-channels -c https://repo.anaconda.com/pkgs/snowflake python=3.8
ii. Activez l’environnement py38_env_tb1.
conda activate py38_env_tb1
iii. Installez les packages Snowpark Python qui seront utilisés dans les fonctions déployées sur Snowflake depuis le canal Anaconda Snowflake.
conda install -c https://repo.anaconda.com/pkgs/snowflake snowflake-snowpark-python numpy pandas scikit-learn joblib cachetools
iv. Installez les packages qui seront utilisés uniquement dans l’environnement Python (interface utilisateur, visualisation, par exemple).
pip install streamlit matplotlib plotly notebook
v. Accédez au référentiel GitHub cloné et lancez le notebook Jupyter.
jupyter notebook
Étape 4 – Exécuter le notebook Jupyter
- Ouvrez et parcourez les cellules du fichier tasty_bytes_snowpark_101.ipynb du notebook Jupyter.
Dépannage
-
Problèmes relatifs à PyArrow : désinstallez
pyarrowavant d’installer Snowpark. -
Créez un autre environnement Python depuis le fichier environment.yml :
i. Sur le terminal, accédez au référentiel GitHub cloné et créez l’environnement.
conda env create -f environment.ymlii . Activez l’environnement.
conda activate py38_env_tb1iii. Lancez le notebook Jupyter.
jupyter notebook
Prototype d’application avec Streamlit
Présentation
Maintenant que vous avez déployé un modèle qui prévoit les futures ventes par équipe de chaque emplacement, trouvez un moyen d’aider les chauffeurs de camionnettes à utiliser ces prévisions pour choisir leur emplacement de stationnement. Vous devez créer un prototype d’application pour montrer à l’équipe d’ingénierie comment un chauffeur de camionnette pourrait utiliser le modèle de prévisions de ventes par équipe. Grâce à l’application, chaque utilisateur pourra choisir une ville et un horaire (midi ou soir), mais aussi afficher les prévisions de ventes par emplacement sur une carte.
Étape 1 – Confirmer les conditions préalables
- L’application Streamlit exploite l’environnement Python, le fichier d’authentification et la fonction définie par l’utilisateur de l’étape 3. Confirmez que vous avez bien :
- Créé l’environnement Python 3.8 py38_env_tb1.
- Rempli le fichier data_scientist_auth.json.
- Exécuté le notebook tasty_bytes_snowpark_101.ipynb.
Étape 2 (facultative) – Vérifier le code
- Ouvrez le fichier streamlit_app.py.
- Identifiez où la connexion à Snowflake s’effectue.
- Identifiez où la fonction d’inférence de modèle définie par l’utilisateur est appelée pour donner des prévisions de ventes par équipe à la volée.
Étape 3 – Lancer l’application
- Sur le terminal, accédez au référentiel GitHub cloné et activez l’environnement Python py38_env_tb1.
conda activate py38_env_tb1 - Lancez l’application.
streamlit run streamlit_app.py - Utilisez le menu déroulant pour sélectionner une ville et afficher les recommandations mises à jour.
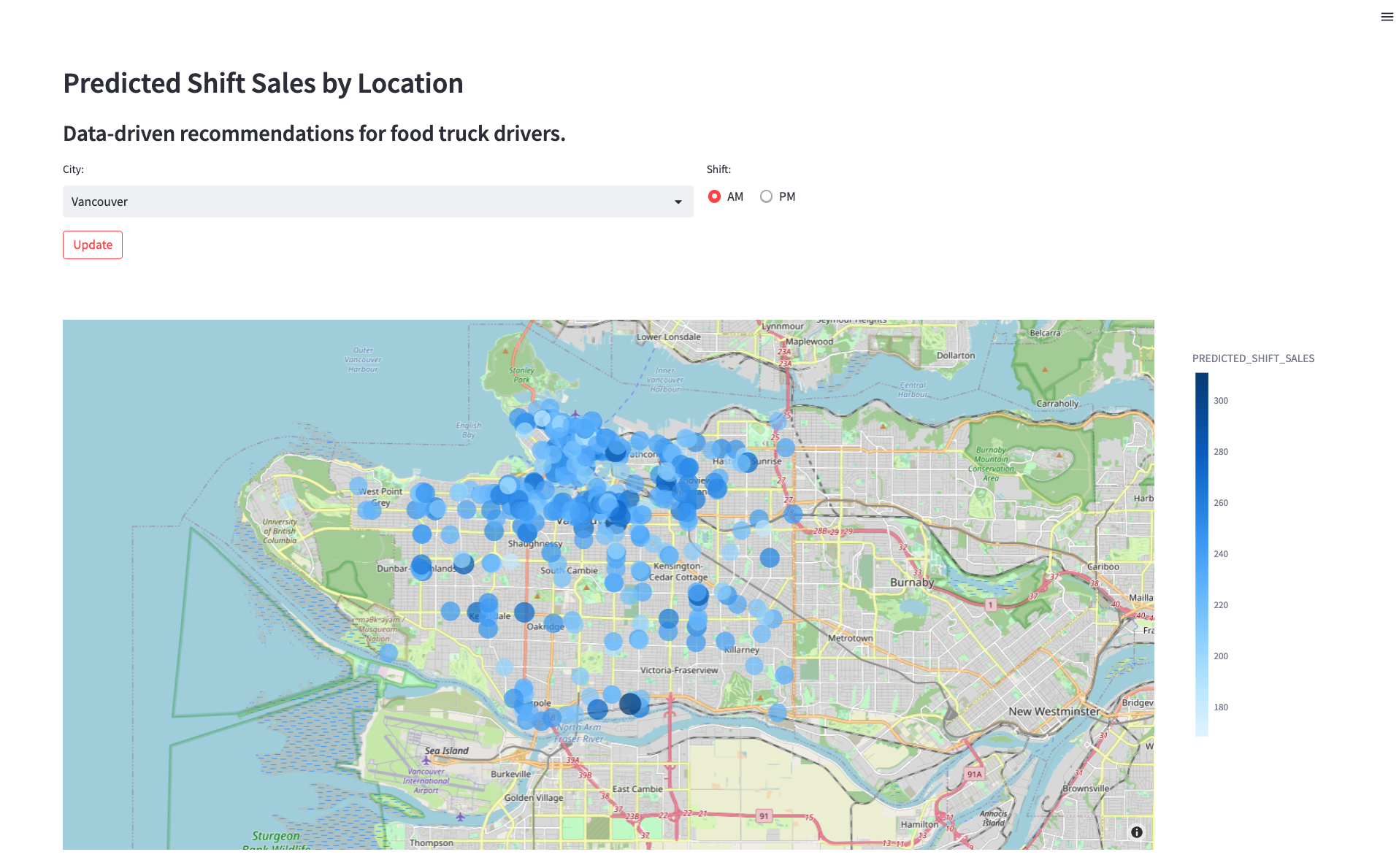
Nettoyage
Présentation des objets créés dans ce guide Quickstart
Snowflake :
- Entrepôt : tasty_dsci_wh
- Base de données : frostbyte_tasty_bytes_dev
- Schéma : brut
- Table : frostbyte_tasty_bytes_dev.raw.shift_sales
- Zone de préparation : frostbyte_tasty_bytes_dev.raw.s3load
- Format de fichier : frostbyte_tasty_bytes_dev.raw.csv_ff
- Schéma : harmonisé
- Table : frostbyte_tasty_bytes_dev.harmonized.shift_sales
- Schéma : analytique
- Tables :
- frostbyte_tasty_bytes_dev.analytics.shift_sales_train
- frostbyte_tasty_bytes_dev.analytics.shift_sales_test
- Vue : frostbyte_tasty_bytes_dev.analytics.shift_sales_v
- Zone de préparation : frostbyte_tasty_bytes_dev.analytics.model_stage
- Procédure : sproc_train_linreg
- Fonction : udf_linreg_predict_location_sales
- Tables :
- Schéma : brut
- Base de données partagée : frostbyte_safegraph
- Table : frostbyte_safegraph.public.frostbyte_tb_safegraph_s
Anaconda :
- Environnement Python py38_env_tb1
GitHub :
- Référentiel cloné : sfguide-tasty-bytes-snowpark-101-for-data-science
Étape 1 – Supprimer des objets Snowflake
- Accédez aux feuilles de calcul, cliquez sur « + » dans le coin supérieur droit pour créer une nouvelle feuille de calcul, puis choisissez « SQL Worksheet » (Feuille de calcul SQL).
- Copiez et exécutez l’instruction SQL suivante dans la feuille de calcul pour supprimer les objets Snowflake créés dans le guide Quickstart.
USE ROLE accountadmin; DROP PROCEDURE IF EXISTS frostbyte_tasty_bytes.analytics.sproc_train_linreg(varchar, array, varchar, varchar); DROP FUNCTION IF EXISTS frostbyte_tasty_bytes.analytics.udf_linreg_predict_location_sales(float, float, float, float, float, float, float, float); DROP DATABASE IF EXISTS frostbyte_tasty_bytes_dev; DROP DATABASE IF EXISTS frostbyte_safegraph; DROP WAREHOUSE IF EXISTS tasty_dsci_wh;
Étape 2 – Supprimer l’environnement Python
- Sur le terminal, exécutez la commande suivante :
conda remove --name py38_env_tb1 --all
Étape 3 – Supprimer le référentiel GitHub cloné
- Sur le terminal, depuis le répertoire où le référentiel GitHub a été cloné, exécutez la commande suivante :
rm -rf sfguide-tasty-bytes-snowpark-101-for-data-science
Conclusion et étapes suivantes
Conclusion
Vous avez réussi ! Vous avez terminé le guide Quickstart Tasty Bytes Snowpark 101 pour la Data Science.
Vous avez :
- Acquis des données de points d’intérêt SafeGraph à partir de la Marketplace Snowflake
- Exploré des données et exécuté le feature engineering avec Snowpark
- Entraîné un modèle dans Snowflake avec une procédure stockée
- Déployé un modèle vers une fonction définie par l’utilisateur
- Créé une application Streamlit pour fournir, à la volée, des prévisions de ventes par équipe par emplacement
Prochaines étapes
Pour continuer à découvrir le Data Cloud Snowflake, cliquez sur le lien ci-dessous pour voir les autres guides Quickstart Tasty Bytes à votre disposition.
This content is provided as is, and is not maintained on an ongoing basis. It may be out of date with current Snowflake instances