React Native 데이터 애플리케이션으로 Tasty Bytes 위치 추천 ML 모델 통합
개요

Snowflake는 ML 모델을 저장 프로시저, 사용자 정의 함수(UDF) 및 사용자 정의 테이블 함수(UDTF)로 배포할 수 있도록 하는 간편한 기능을 통해 데이터 애플리케이션으로 머신러닝 모델을 통합하는 작업을 간소화했습니다. 또한, Snowflake는 RESTful API인 SQL API를 제공하여 배포된 ML 모델을 쿼리할 수 있도록 합니다. 이는 애플리케이션과 ML 모델 간의 원활한 통합을 가능하게 만듭니다.
이 자습서에서 구축하고 있는 애플리케이션은 가상의 푸드 트럭 회사인 Tasty Bytes와 Tasty Bytes의 트럭 기사가 데이터 애플리케이션에서 바로 ML 모델이 제공한 위치 추천을 확인하는 데 도움이 됩니다. 이 위치 추천 ML 모델은 Snowpark를 사용하여 Snowflake 내에 구축됩니다. 따라서 Python 사용자는 Snowflake 플랫폼을 쉽게 활용할 수 있습니다. 이 모델은 과거 매출 데이터와 Snowflake 데이터 마켓플레이스에서 가져온 SafeGraph 날씨 데이터를 사용하여 모델에 더 많은 정보를 제공합니다. 이 자습서는 ML 모델을 트럭 기사 앱에 배포 및 통합하는 프로세스를 안내합니다.
사전 필요 조건 및 지식
- Snowflake에서 사용자, 데이터베이스 및 웨어하우스를 생성하는 데 필요한 권한
- 컴퓨터에서 소프트웨어를 설치 및 실행할 능력
- 기본적인 Git 사용 경험
- SQL에 대한 중급 수준의 지식
- Snowflake에서 SQL를 실행하기 위한 액세스
알아볼 내용
- Snowflake 데이터 마켓플레이스에서 서드 파티 데이터 액세스하기
- 저장 프로시저로 Snowflake에서 모델 훈련하기
- 모델 추론을 위해 사용자 정의 함수에 대해 Snowflake에서 모델 배포하기
- 데이터 앱으로 ML 모델 통합하기
필요한 것
구축할 것
- Snowpark를 사용하여 ML 모델로 구동되는 데이터 애플리케이션
Snowflake에서 데이터 설정
다음을 위해 Snowflake 웹 인터페이스인 Snowsight를 사용하게 됩니다.
- Snowflake 마켓플레이스의 SafeGraph 위치 데이터에 액세스
- Snowflake 객체(웨어하우스, 데이터베이스, 스키마) 생성
- S3에서 교대조 매출 데이터 수집
- 교대조 매출과 SafeGraph 위치 데이터 결합
Tasty Bytes는 전 세계 도시에서 푸드 트럭을 운영합니다. 각 트럭은 매일 2개의 각기 다른 판매 위치를 선택할 수 있습니다. 위치는 SafeGraph 관심 지역에 매핑됩니다. 모델 훈련에서 피처로 사용하기 위해 SafeGraph 마켓플레이스 데이터의 위도와 경도를 교대조 매출 데이터와 결합하고자 합니다.
1단계 - Snowflake 마켓플레이스에서 SafeGraph POI 데이터 획득
-
Snowflake 계정에 로그인합니다.
-
아래 단계와 동영상에 따라 Snowflake 계정에서 SafeGraph 마켓플레이스 목록에 액세스합니다.
- 클릭 -> 홈 아이콘
- 클릭 -> Marketplace
- 검색 -> frostbyte
- 클릭 -> SafeGraph: frostbyte
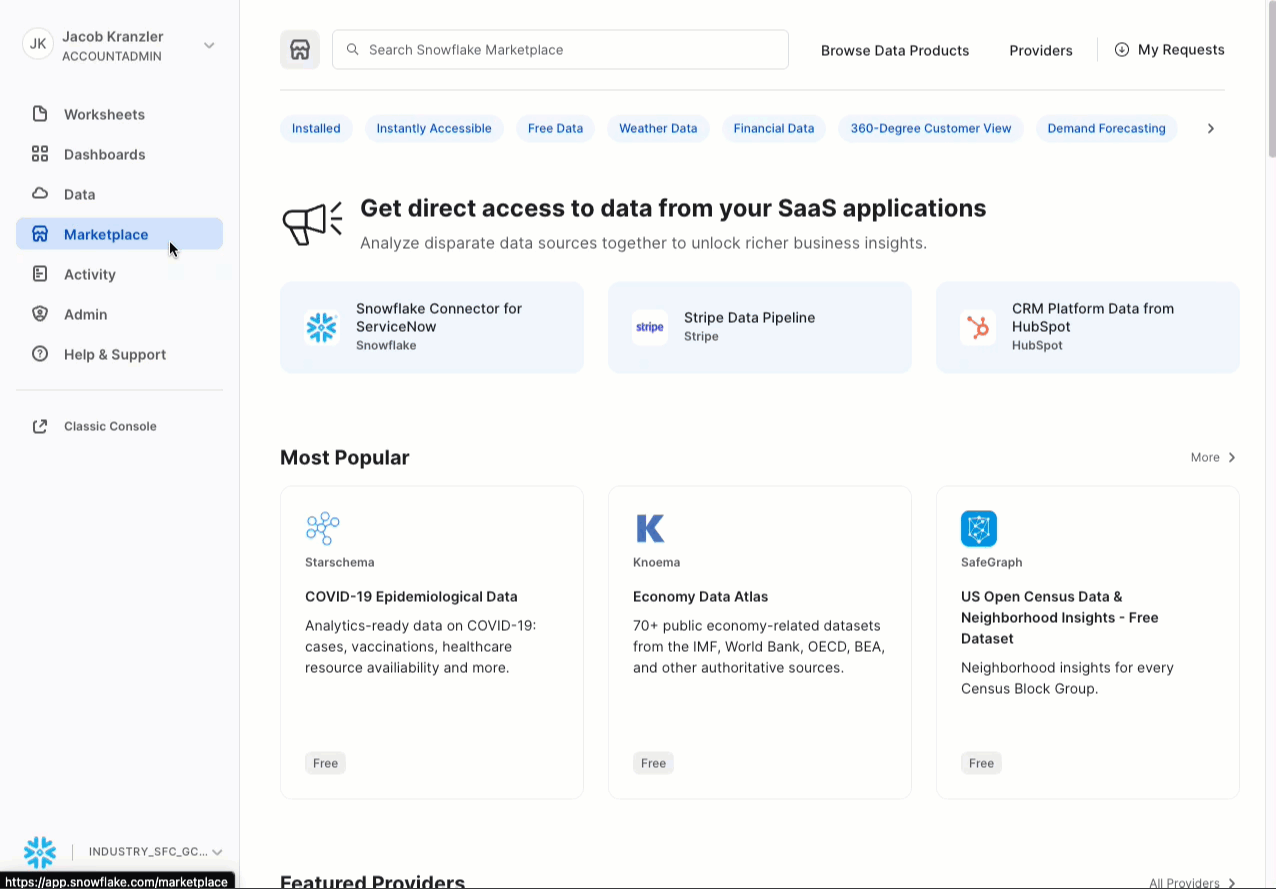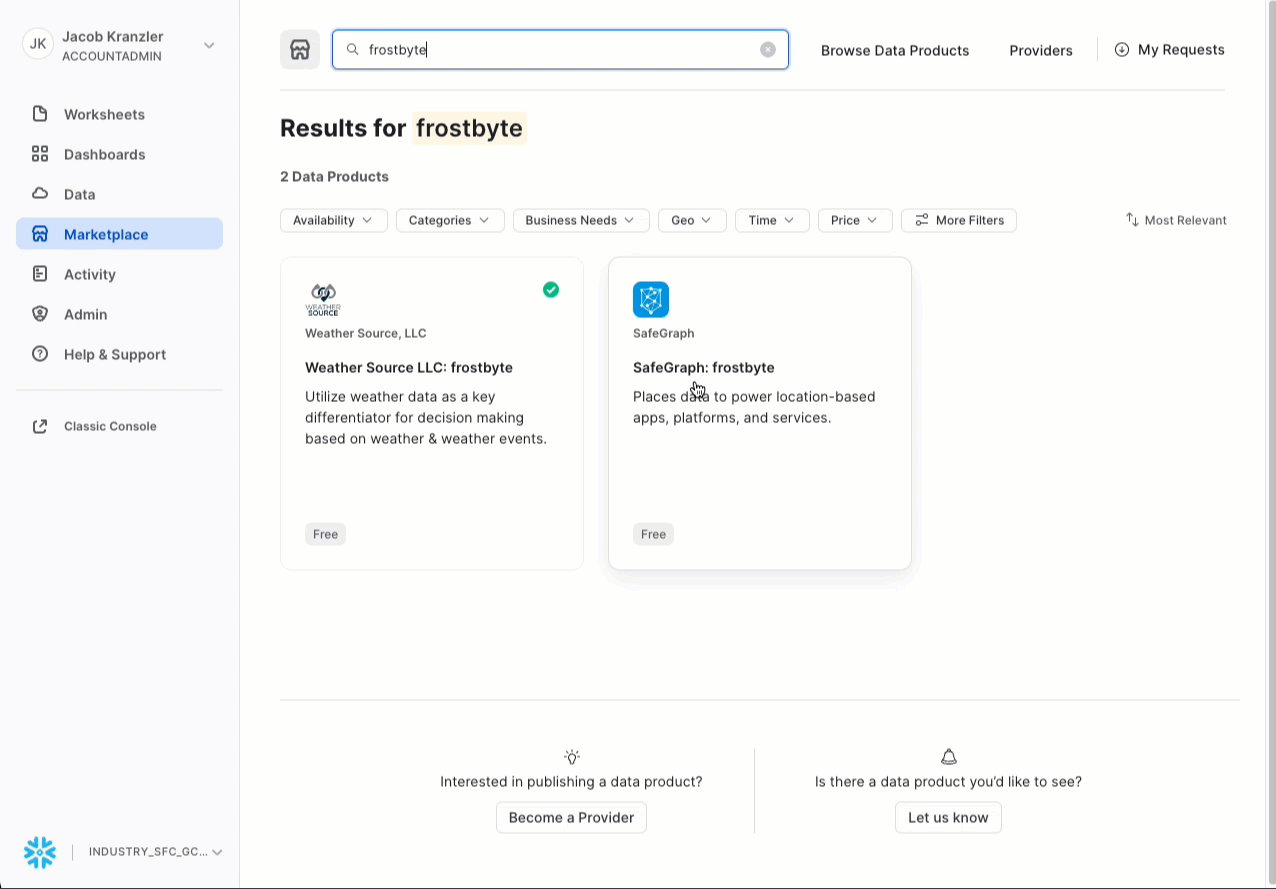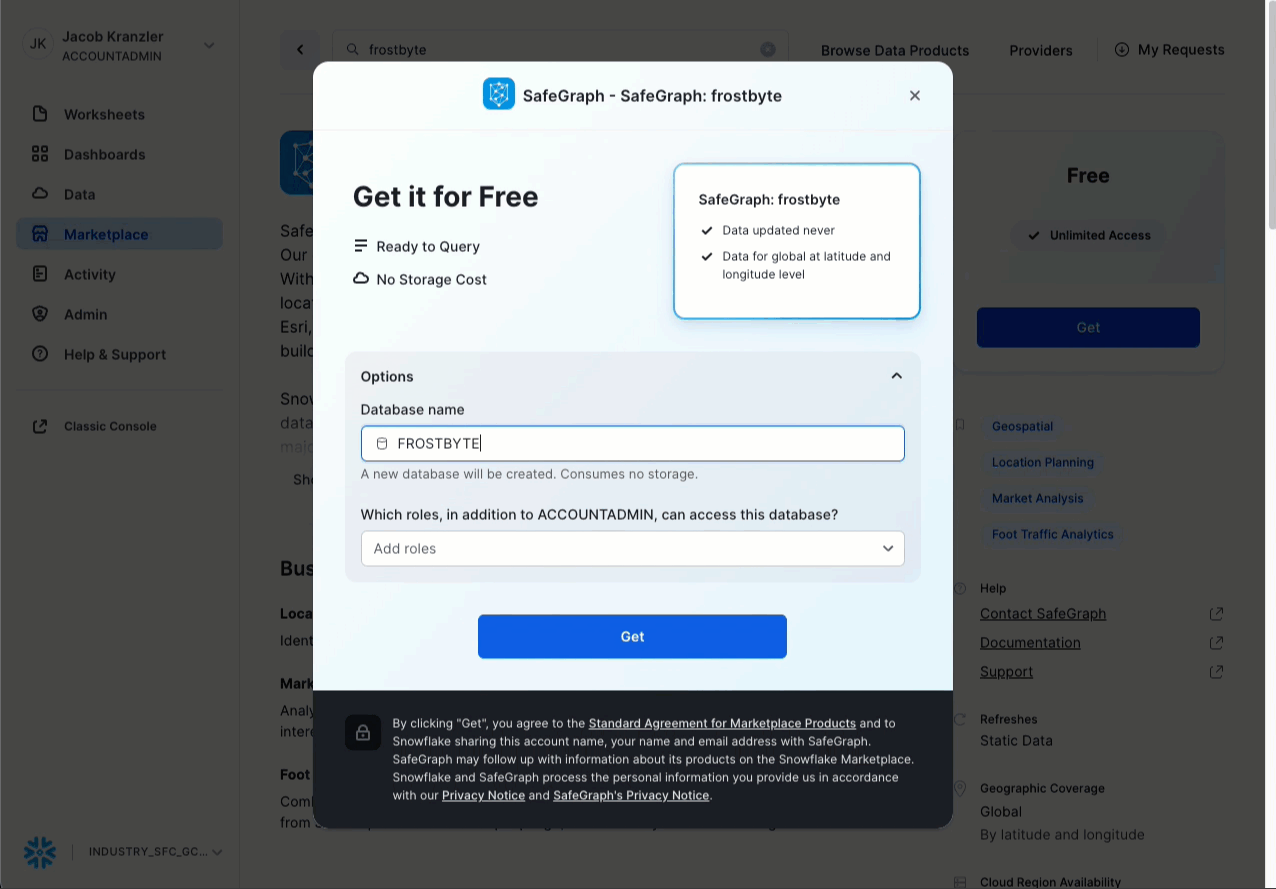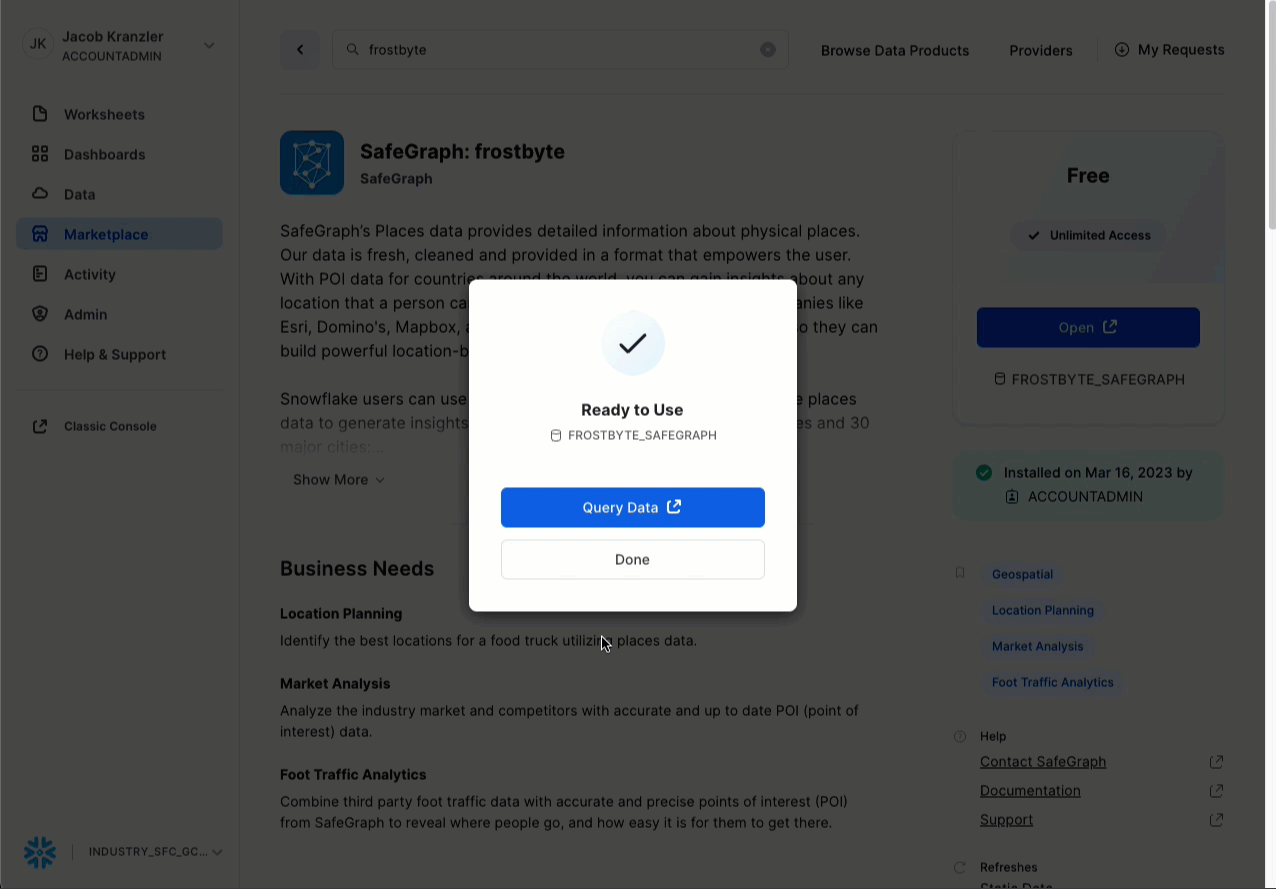
- 클릭 -> Get
- 데이터베이스 이름 바꾸기 -> FROSTBYTE_SAFEGRAPH(전부 대문자)
- 추가 역할에 부여 -> PUBLIC
SafeGraph는 전 세계 모든 장소에 대한 모든 데이터를 제공하는 전 세계적인 지리 공간 데이터 회사입니다. Esri, Tripadvisor, Mapbox 및 Sysco와 같은 고객은 SafeGraph 데이터를 사용하여 고객을 더 잘 이해하고, 신제품을 만들고, 비즈니스를 위한 더 나은 결정을 내립니다.
2단계 - 객체 생성, 데이터 로드 및 데이터 결합
Worksheets로 이동하고, 새로운 워크시트를 생성하기 위해 오른쪽 상단 모서리에 있는 ‘+’를 클릭하고, ‘SQL Worksheet’를 선택합니다.
워크시트에 다음 SQL을 붙여넣고 실행하여 Snowflake 객체(웨어하우스, 데이터베이스, 스키마)를 생성하고, S3에서 가공 전 주문 데이터를 수집하고, 다운스트림 사용을 위해 이를 모델링합니다.
-- use our accountadmin role USE ROLE accountadmin; -- create a development database for data science work CREATE OR REPLACE DATABASE frostbyte_tasty_bytes_ml_app; -- create raw, harmonized, and analytics schemas -- raw zone for data ingestion CREATE OR REPLACE SCHEMA frostbyte_tasty_bytes_ml_app.raw; -- harmonized zone for data processing CREATE OR REPLACE SCHEMA frostbyte_tasty_bytes_ml_app.harmonized; -- analytics zone for development CREATE OR REPLACE SCHEMA frostbyte_tasty_bytes_ml_app.analytics; -- create csv file format CREATE OR REPLACE FILE FORMAT frostbyte_tasty_bytes_ml_app.raw.csv_ff type = 'csv'; -- create an external stage pointing to S3 CREATE OR REPLACE STAGE frostbyte_tasty_bytes_ml_app.raw.s3load COMMENT = 'Quickstarts S3 Stage Connection' url = 's3://sfquickstarts/frostbyte_tastybytes/' file_format = frostbyte_tasty_bytes_ml_app.raw.csv_ff; -- define shift sales table CREATE OR REPLACE TABLE frostbyte_tasty_bytes_ml_app.raw.shift_sales( location_id NUMBER(19,0), city VARCHAR(16777216), date DATE, shift_sales FLOAT, shift VARCHAR(2), month NUMBER(2,0), day_of_week NUMBER(2,0), city_population NUMBER(38,0) ); -- create and use a compute warehouse CREATE OR REPLACE WAREHOUSE tasty_ml_app_wh AUTO_SUSPEND = 60; USE WAREHOUSE tasty_ml_app_wh; -- ingest from S3 into the shift sales table COPY INTO frostbyte_tasty_bytes_ml_app.raw.shift_sales FROM @frostbyte_tasty_bytes_ml_app.raw.s3load/analytics/shift_sales/; -- join in SafeGraph data CREATE OR REPLACE TABLE frostbyte_tasty_bytes_ml_app.harmonized.shift_sales AS SELECT a.location_id, a.city, a.date, a.shift_sales, a.shift, a.month, a.day_of_week, a.city_population, b.latitude, b.longitude, b.location_name, b.street_address FROM frostbyte_tasty_bytes_ml_app.raw.shift_sales a JOIN frostbyte_safegraph.public.frostbyte_tb_safegraph_s b ON a.location_id = b.location_id; -- promote the harmonized table to the analytics layer for data science development CREATE OR REPLACE VIEW frostbyte_tasty_bytes_ml_app.analytics.shift_sales_v AS SELECT * FROM frostbyte_tasty_bytes_ml_app.harmonized.shift_sales; -- view shift sales data SELECT * FROM frostbyte_tasty_bytes_ml_app.analytics.shift_sales_v;
애플리케이션을 위해 사용자 생성
강력한 보안 조치를 보장하려면 개인 계정과 분리된 애플리케이션을 위한 전용 사용자 계정을 생성하는 것이 필수적입니다. 이 새로운 계정은 Snowflake를 쿼리하는 데 활용됩니다. 모범 보안 사례에 따라 해당 계정은 키 쌍 인증을 사용하고 Snowflake 환경 내에서 제한된 액세스를 보유하게 됩니다.
1단계: 인증을 위해 공개 및 개인 키 생성
개인 및 공개 키를 생성하기 위해 다음 명령을 실행합니다. 이러한 키는 사용자를 Snowflake와 인증하는 데 필요합니다.
$ cd ~/.ssh $ openssl genrsa -out snowflake_app_key 4096 $ openssl rsa -in snowflake_app_key -pubout -out snowflake_app_key.pub
2단계: Snowflake에서 사용자와 역할 생성 및 이 새로운 역할에 대한 데이터 액세스 부여
다음 SQL 문을 실행하여 사용자 계정을 생성하고 애플리케이션에 필요한 데이터에 대한 액세스를 부여합니다.
-- use our securityadmin role USE ROLE securityadmin; -- create our tasty_bytes_data_ml_app_demo role CREATE ROLE tasty_bytes_data_ml_app_demo; -- use our accountadmin role USE ROLE accountadmin; -- grant privileges to our tasty_bytes_data_app_demo role GRANT USAGE ON WAREHOUSE tasty_ml_app_wh TO ROLE tasty_bytes_data_ml_app_demo; GRANT USAGE ON DATABASE frostbyte_tasty_bytes_ml_app TO ROLE tasty_bytes_data_ml_app_demo; GRANT USAGE ON SCHEMA frostbyte_tasty_bytes_ml_app.analytics TO ROLE tasty_bytes_data_ml_app_demo; GRANT USAGE ON SCHEMA frostbyte_tasty_bytes_ml_app.harmonized TO ROLE tasty_bytes_data_ml_app_demo; GRANT USAGE ON SCHEMA frostbyte_tasty_bytes_ml_app.raw TO ROLE tasty_bytes_data_ml_app_demo; GRANT SELECT ON ALL VIEWS IN SCHEMA frostbyte_tasty_bytes_ml_app.analytics TO ROLE tasty_bytes_data_ml_app_demo; GRANT SELECT ON ALL VIEWS IN SCHEMA frostbyte_tasty_bytes_ml_app.harmonized TO ROLE tasty_bytes_data_ml_app_demo; GRANT SELECT ON ALL TABLES IN SCHEMA frostbyte_tasty_bytes_ml_app.analytics TO ROLE tasty_bytes_data_ml_app_demo; GRANT SELECT ON ALL TABLES IN SCHEMA frostbyte_tasty_bytes_ml_app.harmonized TO ROLE tasty_bytes_data_ml_app_demo; GRANT SELECT ON ALL TABLES IN SCHEMA frostbyte_tasty_bytes_ml_app.raw TO ROLE tasty_bytes_data_ml_app_demo; -- use our useradmin role USE ROLE useradmin; -- Open the ~/.ssh/snowflake_app_key.pub file from Step 1 and copy the contents starting just after the PUBLIC KEY header, -- and stopping just before the PUBLIC KEY footer for INSERT_RSA_PUBLIC_KEY_HERE. It should be a single line string. CREATE USER data_ml_app_demo RSA_PUBLIC_KEY='<INSERT_RSA_PUBLIC_KEY_HERE>' DEFAULT_ROLE=tasty_bytes_data_ml_app_demo DEFAULT_WAREHOUSE=tasty_ml_app_wh MUST_CHANGE_PASSWORD=FALSE; -- use our securityadmin role USE ROLE securityadmin; GRANT ROLE tasty_bytes_data_ml_app_demo TO USER data_ml_app_demo;
Snowflake에서 ML 모델 훈련 및 배포
개요
Tasty Bytes는 5년에 걸쳐 전년 대비 25%의 매출 성장을 달성하고자 합니다. 이 목표를 지원하고 트럭 군단에 걸쳐 일일 수익을 극대화하려면 데이터 사이언스 팀은 주어진 교대조에서 가장 높은 매출을 올릴 것으로 예측되는 위치로 트럭을 안내하기 위해 ML 모델을 구축해야 합니다.
Worksheets로 이동하고, 새로운 워크시트를 생성하기 위해 오른쪽 상단 모서리에 있는 ‘+’를 클릭하고, ‘SQL Worksheet’를 선택합니다.
워크시트에 다음 SQL을 붙여넣고 실행하여 위치 추천 모델을 훈련 및 배포합니다.
USE ROLE accountadmin; USE DATABASE frostbyte_tasty_bytes_ml_app; USE SCHEMA analytics; USE WAREHOUSE tasty_ml_app_wh; CREATE STAGE IF NOT EXISTS app_stage; -- Create stored proc for shift table CREATE OR REPLACE PROCEDURE build_shift_feature_table() RETURNS string LANGUAGE python RUNTIME_VERSION = '3.8' PACKAGES = ('snowflake-snowpark-python') HANDLER = 'create_table' AS $$ def create_table(session): import snowflake.snowpark.functions as F import snowflake.snowpark.types as T from snowflake.snowpark import Window # Create DataFrame snowpark_df = session.table("frostbyte_tasty_bytes_ml_app.analytics.shift_sales_v") # Create rolling average window_by_location_all_days = ( Window.partition_by("location_id", "shift") .order_by("date") .rows_between(Window.UNBOUNDED_PRECEDING, Window.CURRENT_ROW - 1)) snowpark_df = snowpark_df.with_column( "avg_location_shift_sales", F.avg("shift_sales").over(window_by_location_all_days)) # Impute snowpark_df = snowpark_df.fillna(value=0, subset=["avg_location_shift_sales"]) # Encode snowpark_df = snowpark_df.with_column("shift", F.iff(F.col("shift") == "AM", 1, 0)) # Get date date_tomorrow = snowpark_df.filter(F.col("shift_sales").is_null()).select(F.min("date")).collect()[0][0] # Filter feature_df = snowpark_df.filter(F.col("date") == date_tomorrow).drop(F.col("shift_sales")) # Get Location Detail location_df = session.table("frostbyte_tasty_bytes_ml_app.analytics.shift_sales_v").select("location_id", "location_name", "street_address") # Join feature_df = feature_df.join(location_df, feature_df.location_id == location_df.location_id, "left") .drop(location_df.location_id) .drop(location_df.location_name) .drop(location_df.street_address) .rename(feature_df.location_id, "location_id") .rename(feature_df.location_name, "location_name") .rename(feature_df.street_address, "street_address") # Save table feature_df.write.mode("overwrite").save_as_table("frostbyte_tasty_bytes_ml_app.analytics.shift_features") return "SUCCESS" $$; -- Call sproc to create feature table Call build_shift_feature_table(); -- Set permissions GRANT ALL PRIVILEGES ON TABLE frostbyte_tasty_bytes_ml_app.analytics.shift_features to tasty_bytes_data_ml_app_demo; -- Create training stored procedure CREATE OR REPLACE PROCEDURE SPROC_TRAIN_LINREG() RETURNS STRING LANGUAGE PYTHON RUNTIME_VERSION = '3.8' PACKAGES = ('snowflake-snowpark-python','scikit-learn','joblib') HANDLER = 'train_model' AS $$ def train_model(session): import snowflake.snowpark.functions as F import snowflake.snowpark.types as T from snowflake.snowpark import Window # Create DataFrame snowpark_df = session.table("frostbyte_tasty_bytes_ml_app.analytics.shift_sales_v") # Create rolling average window_by_location_all_days = ( Window.partition_by("location_id", "shift") .order_by("date") .rows_between(Window.UNBOUNDED_PRECEDING, Window.CURRENT_ROW - 1)) snowpark_df = snowpark_df.with_column( "avg_location_shift_sales", F.avg("shift_sales").over(window_by_location_all_days)) # Impute snowpark_df = snowpark_df.fillna(value=0, subset=["avg_location_shift_sales"]) # Encode snowpark_df = snowpark_df.with_column("shift", F.iff(F.col("shift") == "AM", 1, 0)) # Get date date_tomorrow = snowpark_df.filter(F.col("shift_sales").is_null()).select(F.min("date")).collect()[0][0] # Filter to historical historical_snowpark_df = snowpark_df.filter(F.col("shift_sales").is_not_null()) # Drop historical_snowpark_df = historical_snowpark_df.drop("location_id", "city", "date") # Split train_snowpark_df, test_snowpark_df = historical_snowpark_df.randomSplit([0.8, 0.2]) # Import packages from sklearn.linear_model import LinearRegression from joblib import dump feature_cols = ["MONTH", "DAY_OF_WEEK", "LATITUDE", "LONGITUDE", "CITY_POPULATION", "AVG_LOCATION_SHIFT_SALES", "SHIFT"] target_col = "SHIFT_SALES" # Get training data df = train_snowpark_df.to_pandas() # Set inputs X and outputs y X = df[feature_cols] y = df[target_col] # Train model model = LinearRegression().fit(X, y) # Save model model_name = "linreg_location_sales_model.sav" dump(model, "/tmp/" + model_name) session.file.put( "/tmp/" + model_name, "@APP_STAGE", auto_compress=False, overwrite=True ) return "SUCCESS" $$; -- Train model Call sproc_train_linreg(); -- Deploy the model as a UDF CREATE OR REPLACE FUNCTION udf_predict_location_sales_prod(arg1 FLOAT,arg2 FLOAT, arg3 FLOAT,arg4 FLOAT, arg5 FLOAT,arg6 FLOAT, arg7 FLOAT) RETURNS FLOAT LANGUAGE PYTHON RUNTIME_VERSION=3.8 IMPORTS=('@APP_STAGE/linreg_location_sales_model.sav') PACKAGES=('scikit-learn','joblib','cloudpickle==2.0.0','pandas', 'cachetools') HANDLER='predict' as $$ import pandas import cachetools from _snowflake import vectorized @cachetools.cached(cache={}) def load_model(filename): import joblib import sys import os import_dir = sys._xoptions.get("snowflake_import_directory") if import_dir: with open(os.path.join(import_dir, filename), 'rb') as file: m = joblib.load(file) return m @vectorized(input=pandas.DataFrame) def predict(X: pandas.DataFrame) -> pandas.Series: # Load the model model = load_model("linreg_location_sales_model.sav") # Get predictions predictions = model.predict(X) # Return rounded predictions return predictions.round(2) $$; -- Set permissions GRANT ALL PRIVILEGES ON FUNCTION udf_predict_location_sales_prod(FLOAT,FLOAT,FLOAT, FLOAT,FLOAT,FLOAT,FLOAT) to tasty_bytes_data_ml_app_demo;
SQL API를 사용하여 ML 모델에서 데이터 가져오기 및 데이터 애플리케이션으로 통합
실행할 애플리케이션은 React Native에서 작성되었습니다.
1단계: 소스 코드 가져오기
git clone https://github.com/sf-gh-sjasti/IntegrationTastyBytesMLModelInDataApp.git reactNativeMLApp을 사용하여 리포지토리를 복제합니다.cd reactNativeMLApp폴더로 이동합니다.- 종속성을 설치하기 위해
npm install을 실행합니다.
2단계: 애플리케이션 구성
- VS Code 또는 선호하는 IDE에서
reactNativeMLApp폴더를 엽니다. .env파일을 열고 개인 키로PRIVATE_KEY값을 업데이트합니다. 헤더(-----BEGIN RSA PRIVATE KEY-----) 및 푸터(-----END RSA PRIVATE KEY-----)를 비롯한 전체 개인 키를~/.ssh/snowflake_app_key에서 복사하여 붙여넣습니다.- us-west 리전에 있다면 Snowflake 계정으로
SNOWFLAKE_ACCOUNT_IDENTIFIER를 업데이트합니다. 또는, us-west 리전 외부에 있다면SNOWFLAKE_ACCOUNT_IDENTIFIER를 '.'으로 업데이트합니다. Snowflake에서 snowflake_account 값을 가져오려면 Snowsight에서SELECT CURRENT_ACCOUNT()를 실행합니다. Snowflake에서 리전 값을 가져오려면 Snowsight에서SELECT CURRENT_REGION()을 실행합니다. SNOWFLAKE_ACCOUNT_IDENTIFIER 및 SNOWFLAKE_ACCOUNT는 us-west에서도 동일합니다. - Snowflake 계정으로
SNOWFLAKE_ACCOUNT를 업데이트합니다. - 자신의 공개 키 지문으로
PUBLIC_KEY_FINGERPRINT를 업데이트합니다. 공개 키 지문을 가져오려면 Snowsight에서DESCRIBE USER data_app_demoSQL을 실행하여 RSA_PUBLIC_KEY_FP 속성 값을 가져옵니다.
3단계: 소스 코드 검토
SQL API를 사용하여 Snowflake와 인증하기 위해 키 쌍 인증을 사용합니다. JWT 토큰 생성 방법을 이해하기 위해 Tokens.js를 참고할 수 있습니다. Locations.js에는 Locations 화면을 렌더링하기 위한 소스 코드가 있습니다. 또한, SQL API와 필요한 헤더를 사용하여 UDF를 쿼리하는 방법을 알아보기 위해 이 파일을 참고할 수 있습니다.
4단계: 애플리케이션 테스트
npx expo start --clear를 실행하고w키를 눌러 웹 브라우저에서 앱을 실행합니다.- 이렇게 하면 웹 브라우저에서 앱이 시작됩니다.
- 시작된 후 InQueue Orders 화면을 확인할 수 있습니다.

정리
Snowsight Worksheets로 이동하고, 새로운 워크시트를 생성하기 위해 오른쪽 상단 모서리에 있는 ‘+’를 클릭하고, ‘SQL Worksheet’를 선택합니다. 워크시트에 다음 SQL을 붙여넣고 실행하여 Quickstart에서 생성한 Snowflake 객체를 드롭합니다.
USE ROLE accountadmin; DROP DATABASE frostbyte_tasty_bytes_ml_app; DROP WAREHOUSE tasty_ml_app_wh; USE ROLE securityadmin; DROP USER data_ml_app_demo; DROP ROLE tasty_bytes_data_ml_app_demo;
결론
결론
끝났습니다! React Native 데이터 애플리케이션에 Tasty Bytes 위치 추천 ML 모델 통합 Quickstart를 성공적으로 완료하셨습니다.
이를 진행하면서 배운 내용은 다음과 같습니다.
- Snowflake 데이터 마켓플레이스에서 서드 파티 데이터 획득
- 저장 프로시저로 Snowflake에서 ML 모델 훈련
- 모델 추론을 위해 Snowflake에서 UDF로 ML 모델 배포
- 데이터 앱으로 ML 모델 통합
다음 단계
위치 추천 ML 모델에 대한 상세 정보는 Tasty Bytes - 데이터 사이언스를 위한 Snowpark 101 Quickstart를 참조하십시오.
Snowflake 데이터 클라우드에서의 여정을 계속하려면 아래 링크를 방문하여 사용 가능한 더 많은 Tasty Bytes - Quickstart를 확인하십시오.
This content is provided as is, and is not maintained on an ongoing basis. It may be out of date with current Snowflake instances